
NomosDA vs Other Data Availability Solutions
This article will compare NomosDA with the data availability solutions provided by Ethereum, Celestia, and Avail.


As blockchains continue to scale, they are increasingly tasked with finding a way to guarantee that blockchain data is available for download, without requiring network participants to download the entire data. This challenge, known as the “data availability problem”, has prompted the emergence of a variety of corresponding data availability (DA) solutions. For Nomos, our team has designed a custom DA solution known as NomosDA, which was engineered to work best with the following features of the Nomos network:
- Decentralization: For Nomos, decentralisation is critically important. Therefore, permissioned DA schemes involving a Data Availability Committee (DAC) were avoided. Schemes that require some nodes to store the entire blob data were also off the list due to the disproportionate role played by these “supernodes”.
- Scalability: NomosDA was designed to minimise the amount of data sent to DA nodes, reducing the communication bottleneck and allowing more nodes to participate in the DA process.
To get a better sense of why Nomos uses a purpose-built solution, this article will compare NomosDA with the data availability solutions provided by Ethereum, Celestia, and Avail. The comparison will encompass the solutions’ different architectures and performance, all while focusing on the Nomos network’s unique requirements.
Summary Table
The table below summarises the key differences between NomosDA, Ethereum’s Danksharding, Celestia, and Avail DA.
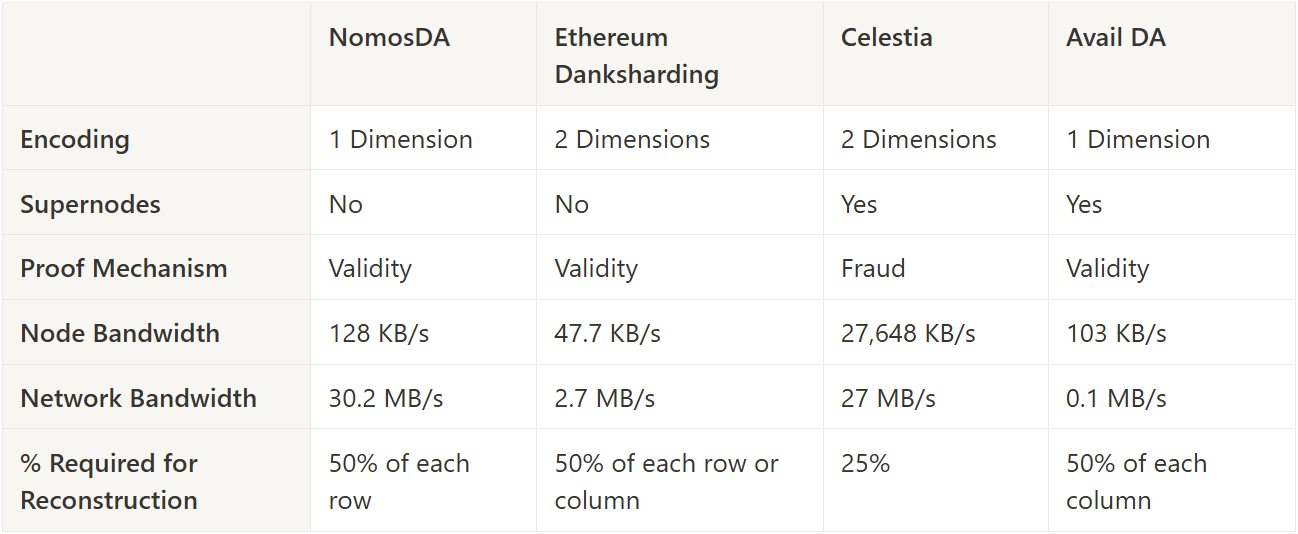
The calculations used to obtain the figures in the table are available in the appendix at the end of this article.
NomosDA
NomosDA provides an assurance that all data from Nomos zones - referred to as blobs - are accessible and verifiable by every network participant. The protocol describes the way that blob data is correctly encoded by zone executors, distributed & verified by Nomos validators, and sampled by light clients. NomosDA also provides a reconstruction procedure for a client wishing to download an entire incomplete blob. While NomosDA is explained in detail in this blog post, we will include a more concise description below to facilitate comparisons with the other solutions. It should be noted that NomosDA is undergoing a process of active research, and therefore this section only describes the first version of the solution, which is subject to further improvement.
In the encoding phase, a zone executor will expand the blob data using Reed-Solomon erasure coding with an expansion factor of 2. This will have the effect of doubling the size of the rows in the blob matrix, with the original data (row indices 0 to k-1) remaining intact alongside the new, expanded data (row indices k to 2k-1).
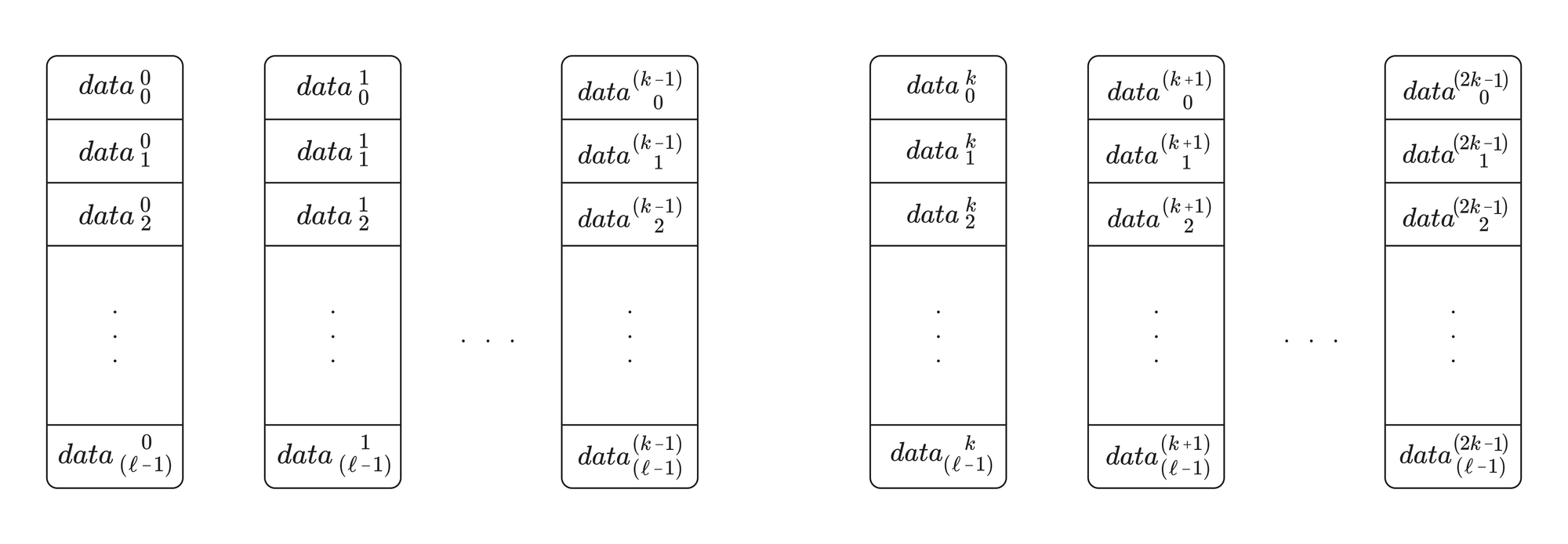
The executor will also calculate various cryptographic commitments and proofs to enable validators to verify the data’s integrity.
NomosDA then proceeds with the dispersal phase, in which the executor splits up their encoded blob and sends each column to a node in a group of participating validators known as a subnet. This node sends the column data it received to the other nodes in its subnet, and all the nodes use the published commitments and proofs to verify that their column was correctly encoded.
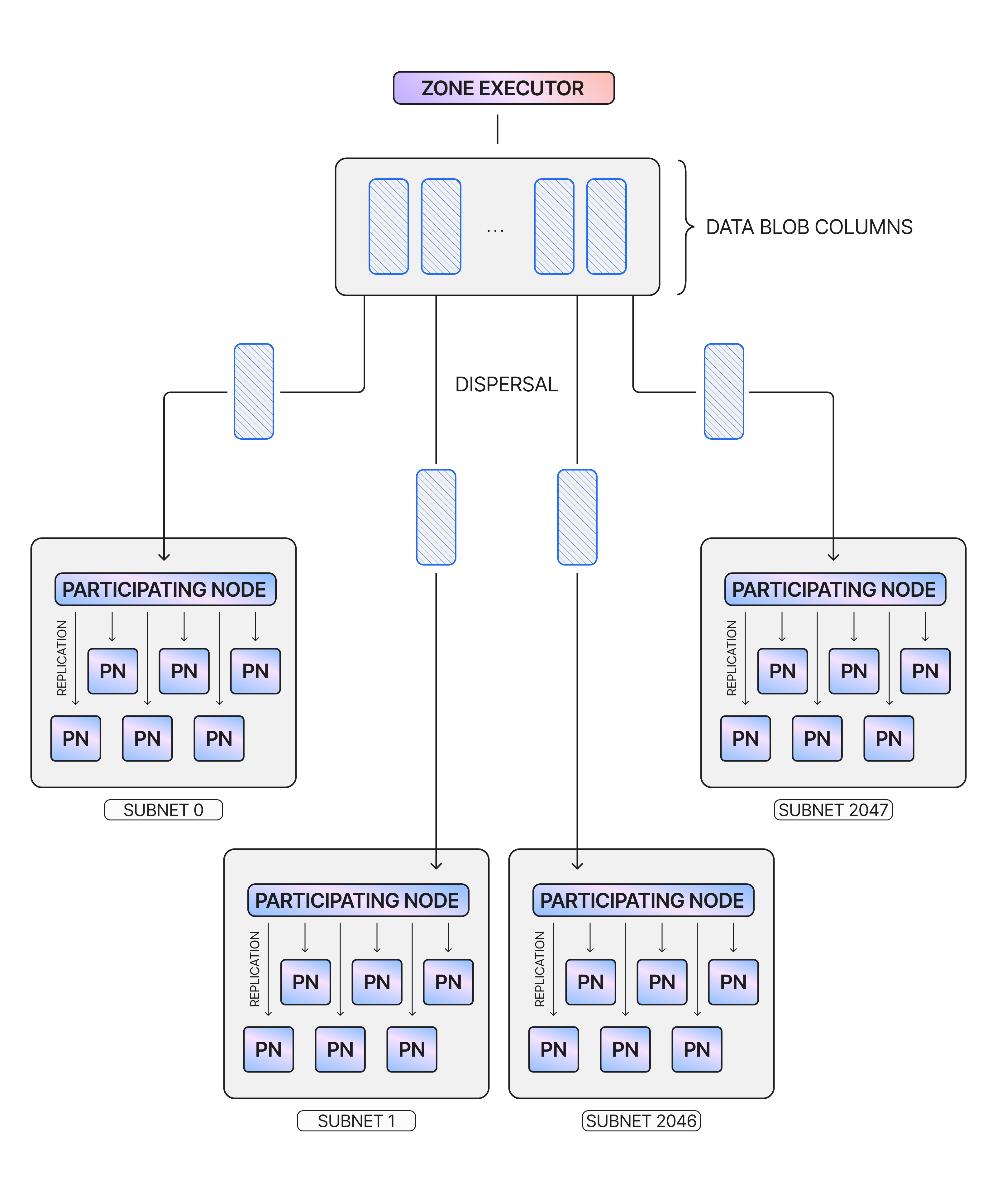
Once dispersed, the data can be sampled by anybody with Data Availability Sampling (DAS). Choosing a random set of columns, a sampling client sends requests to the corresponding nodes hosting those columns. These samples, combined with the relevant commitments and proofs pulled from the chain, are used to obtain a local opinion on whether the data is available or not.
Reconstruction is an option available to clients that choose to download an entire blob. Such a client can use the error-correcting properties of Reed-Solomon codes to reconstruct the blob data, so long as at least 50% of every row is intact.
Analysis
NomosDA was designed to provide a resilient and maximally-distributed way for clients to download zone data, as well as protection against data withholding attacks from zone executors. Therefore, it enables easy reconstruction for the data availability guarantee period, but provides no local reconstruction or direct download of the entire data (such as from a supernode).
The NomosDA design places a high emphasis on decentralization, and therefore does not require any node to download the entire blob data. This is true even for reconstruction, which is accomplished without a reliance on such “supernodes”. NomosDA also uses validity proofs to verify correct encoding, leading to faster finality times than with fraud proofs. NomosDA’s network bandwidth is the highest at 30.2 MB/s, but comes with tradeoffs such as a big computation burden for Executors, more expensive reconstruction, and heavy sampling of columns. NomosDA nodes have to download 128 KB/s, which is higher than some other solutions’ node bandwidth.
This section describes the initial version of NomosDA. Subsequent versions are expected to have better properties for encoding performance and light node sampling.
Ethereum Danksharding
The Ethereum blockchain implemented Proto-Danksharding in March of 2024, which introduced blobs for rollup data as part of efforts to scale the network. While the completion of this process, known as Danksharding, is still several years away, the basic architecture is well-known and will be described here for completeness. In this section, we rely on this proposal on the Ethereum research forums to provide an example for how Danksharding may be implemented in the future.
Ethereum’s Danksharding is fairly similar to NomosDA, albeit with some key differences. In Danksharding, rollups send blob-carrying transactions along with their associated commitments to Ethereum block builders. Each builder will verify the blobs against their commitments and create an encoded block from the valid blobs it received. This encoding is done with Reed-Solomon coding, using a bivariate polynomial to expand the original block by a factor of 2 along both dimensions, quadrupling its size. The commitments are expanded using RS coding as well.
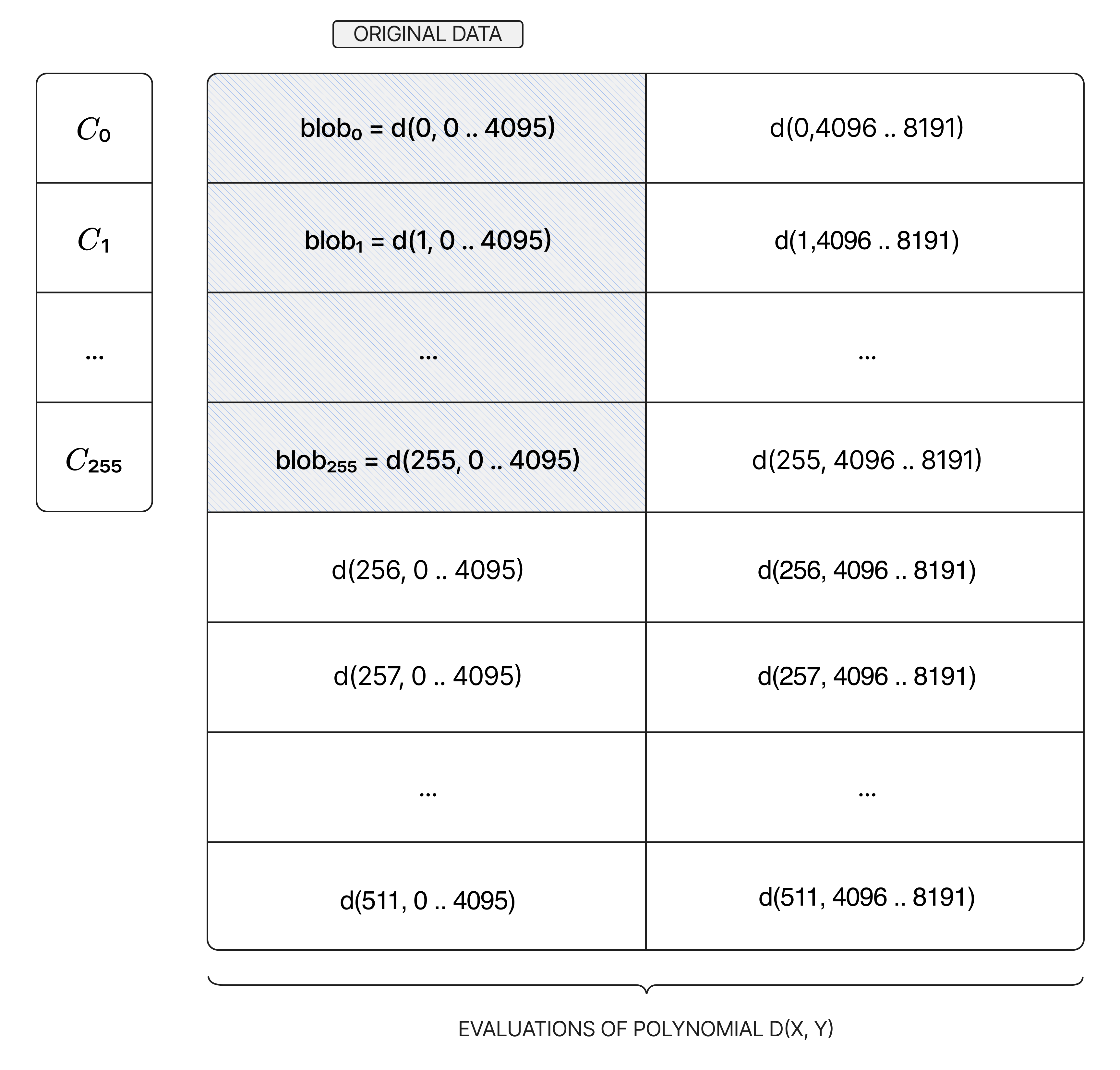
In the dispersal phase, the block builder reimagines the encoded 512 x 8192 element matrix as a 512 x 512 square matrix, where each element (known as a sample) in the square matrix is a 1 x 16 element row vector from the original encoded matrix. In essence, columns in the square matrix become equivalent to 16 columns in the original encoded matrix. The block builder then sends the following “package” to Ethereum validators:
- 50% of data from four consecutive columns from the square matrix (the rest reconstructed locally),
- Evaluation proofs for each element in the rows and columns, and
- The set of all blob commitments.
The exact columns are determined based on the column subnet the validator is assigned to, allowing them to receive this package from their peers in the subnet if they did not receive it directly from the block builder. This is similar to the approach used by NomosDA, except that each Danksharding subnet contains 4 consecutive columns. Each validator uses the data it receives to verify that its rows and columns were correctly encoded.
Light clients can use Data Availability Sampling to request samples from validators in the relevant subnets, who reply with the sample data together with its evaluation proofs. The sampling client can verify these proofs against the published commitments to obtain an assurance of data availability for that block. Validators also use DAS to ensure that blocks they are attesting to (and their predecessors) are available and valid.
A reconstruction client can retrieve the entire block, including the original data, so long as 50% of each row and column data can be obtained from validators. Additionally, validators can reconstruct their own hosted columns with at least 50% of the data in their sample, a process known as local reconstruction.
Analysis
Danksharding supports local reconstruction, while a NomosDA node that loses its column data must retrieve it from other nodes in its subnet. Like NomosDA, Danksharding also does not rely on DA supernodes that download the entire data, and uses validity proofs to ensure that the encoding was performed correctly. Instead, each Ethereum node downloads just 47.7 KB/s of data. However, in part due to 2 dimensional expansion, Ethereum has a fairly low network bandwidth at 2.7 MB/s, and allows light clients to sample chunks rather than whole columns.
Celestia
Celestia is a modular blockchain that provides a consensus and data availability layer to layer 2 chains that focus on other blockchain functions, such as execution or settlement. Using Celestia, these chains gain access to a large network of DA validators while optimising their execution for their specific use cases. The following section is based on the Mammoth Mini testnet figures.
In order to associate blobs with their chain of origin, blob data is sent to Celestia together with a namespace used to identify the rollup it was sent from. In the encoding phase, the block producer splits the blobs it receives into shares, which are equal-sized portions of blob data combined with a namespace prefix. These shares are arranged in a square matrix, grouping shares with the same namespace together.
The block producer proceeds to expands the matrix using two dimensional Reed-Solomon erasure coding, with the extended data taking its own unique namespace. Unlike in Danksharding, which uses bivalent polynomials to expand along both dimensions, Celestia’s encoding is essentially one dimensional expansion conducted three times: first, expanding the rows, then the columns, and finally expanding the rows of the expanded column data to complete the square.
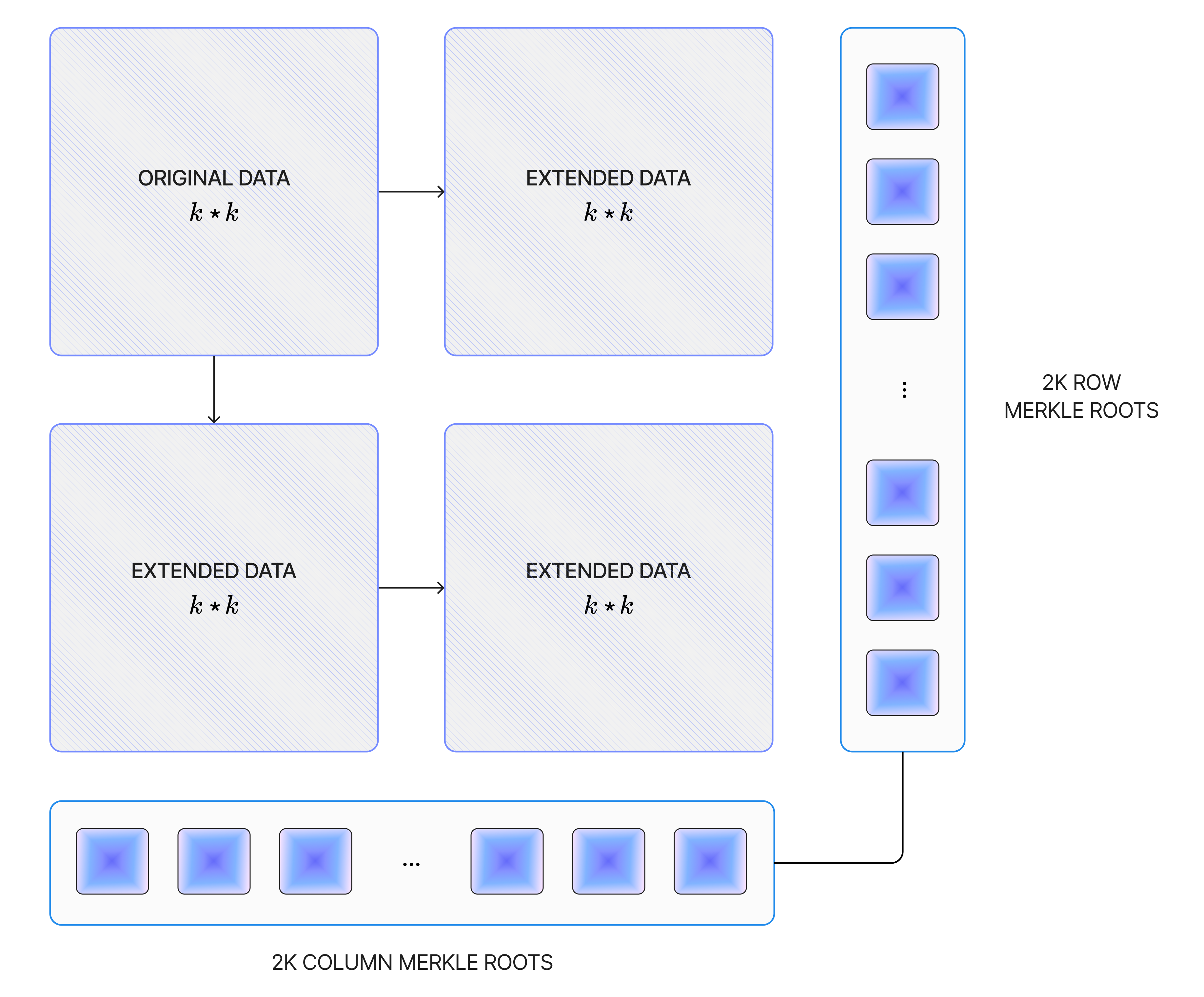
The block producer will also generate Namespaced Merkle Trees (NMTs) for every row and column of the expanded matrix. NMTs are a type of Merkle tree where the data is ordered according to its namespace, and every node in the tree includes the namespace range of its descendants. The commitment to the data is calculated as the root of the binary Merkle tree built from the roots of the row and column NMTs.
The encoded block data is downloaded by every full node, relying on fraud proofs to ensure that the data was encoded correctly. If the encoding is not correct, a full node can use its data to generate a proof of this fact and share it with other full and light nodes. This proof is verified by reconstructing just one row or column, resulting in the rejection of the block. Therefore, if a set challenge period passes without any valid fraud proofs posted, the block is assumed to be correct.
In Celestia, light clients engage in DAS to gain an assurance of the availability of the data, verifying sampled shares against the relevant commitments. They also publish these samples to the network, allowing full nodes to reconstruct the original data if they can obtain at least 25% of the total from other nodes.
Analysis
A major downside of Celestia is its reliance on fraud proofs to ensure correct data encoding. Due to the requirement for a challenge period to allow for fraud proofs to be posted, an assurance of data availability necessarily takes more time than using validity proofs. Celestia relies on full nodes to each download the entire data (29.3 MB/s), a quality that was avoided in NomosDA. Additionally, Celestia’s two dimensional expansion creates extra work for block producers compared with one dimensional expansion. However, this expansion is necessary to allow light clients to verify encoding fraud proofs. On the Mammoth Mini testnet, Celestia boasts a network bandwidth of 27 MB/s.
The Celestia community has recently discussed moving away from Reed-Solomon coding and fraud proofs to using ZODA (Zero-Overhead Data Availability). ZODA would, in theory, allow the encoded data square to serve as the validity proof of its own correctness. The current Celestia roadmap also sets a goal for Celestia blocks to reach 1 GB with 83 MB/s network bandwidth. However, these changes are still far from being implemented at the time of writing.
Avail DA
Avail DA, like Celestia, provides a data availability layer to rollups and other layer 2 chains according to the modular blockchain model. However, it has some key differences that make it worthy of analysis in its own right.
In Avail DA’s encoding phase, blobs sent from various chains are bundled together into a matrix by the block producer. The block producer generates commitments to each row of the matrix, and uses Reed-Solomon coding to extend the data columns as well as the commitment column. This commitment column is broadcasted as the block header.
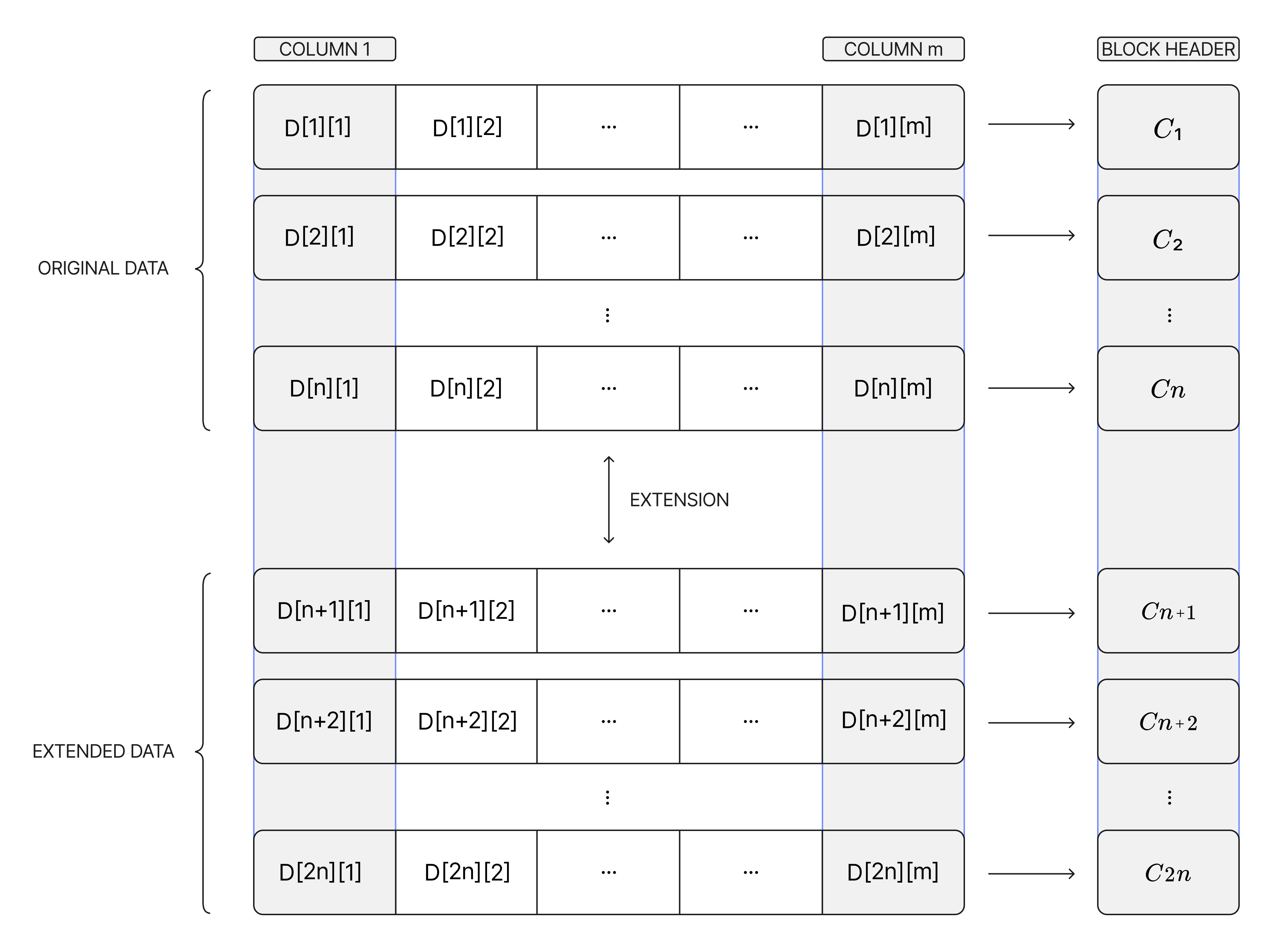
The original block is proposed and distributed to all classical full nodes, which download it in its entirety. They rerunning the encoding process on this original data and comparing the result with the published commitments to verify that the block producer encoded the data correctly. Column full nodes, by contrast, only download one column of the matrix, together with relevant evaluation proofs sent by the block producer. They verify these proofs by extending the original part of their column and the proof column and making sure that the proofs are valid.
Light clients engage in DAS by sampling one data chunk and its associated proof from full nodes, gossiping their samples to other light clients. Using this peer-to-peer gossip network, light clients can reconstruct the original data and allow other light clients to sample directly from this network rather than from full nodes.
Analysis
Avail DA is optimised for quick and easy data retrieval and reconstruction, providing fast data availability guarantees than Celestia due to its use of validity proofs for encoding correctness. Avail DA’s introduction of column full nodes makes it easier for clients to participate in the DA process. However, Avail DA still relies on classical full nodes in case a column full node fails, downloading 103 KB/s. In this sense, it has a greater potential for centralisation than NomosDA or Danksharding. Like NomosDA, Avail DA only expands the encoded data along one dimension. Avail DA’s network bandwidth is also fairly low, at 0.1 MB/s.
Conclusion
To meet the Nomos network’s dual requirements of decentralisation and scalability, it was necessary for our team to design a data availability solution with a good balance between these qualities. Celestia’s use of full nodes and fraud proofs made it totally unsuitable for our use case. Danksharding, the solution most similar to NomosDA, exhibits good decentralisation but has a relatively low network bandwidth. Avail DA’s reliance on supernodes makes it suboptimal for use in Nomos, and its network bandwidth leaves much to be desired. Ultimately, it is clear that NomosDA is the best data availability solution that fulfills the unique needs of the Nomos network.
That said, there is still room for improvement. The Nomos team is actively working on a new-and-improved version of NomosDA, which is expected to reduce the burden on zone executors by improving the encoding phase’s performance, and making sampling by light clients easier as well. As with the Nomos project as a whole, NomosDA is a work in progress, constantly improving to best fulfill the needs of the Nomos network.
Sources and Further Reading
- Introduction to NomosDA
- A Guide to Selecting the Right Data Availability Layer
- Data availability sampling and danksharding: An overview and a proposal for improvements
- From 4844 to Danksharding: a path to scaling Ethereum DA
- Celestia's data availability layer
- Avail: A Unifying Blockchain Network (2024)
Appendix: Calculations
NomosDA
Settings:
- Maximum original blob size: 1 MB (about 1024 columns and 33 rows)
- Node bandwidth: 1 Mb/s
- Subnets: 2048 (1024 columns of original data)
Node Bandwidth:
- 1 Mb/s = 128 KB/s
Network Bandwidth:
- Each node can take 1 Mb/s of total data
- Commitments and proofs per node:
- 33 row commitments + 33 proofs for each element in column + 1 column commitment + 1 column proof + 1 aggregate column commitment = 69 commitments and proofs
- 69 * 48 bytes per KZG commitment and proof = 3312 B
- Data per node:
- 33 elements per column * 31 bytes per element = 1023 B
- Every column sent to a node consists of 1023 B data and 3312 B commitments and proofs
- Therefore, 1023 / (1023 + 3312) / 2 (half of dispersed data is extended) = 11.8% of total data bandwidth is used for original data
- 1 Mb/s * 11.8% = 0.118 Mb/s of original data bandwidth per node
- 0.118 Mb/s * 2048 subnets = 30.2 MB/s
Ethereum Danksharding
Settings:
- Maximum original block size: 32 MB (256 rows by 256 columns)
- Block time: 12 s
- Subnets: 1024 (512 expanded rows + 512 expanded columns)
- Columns per subnet: 4
- Custody requirement for each node: 1 subnet
- Note: only 50% of each row and column are downloaded due to local reconstruction
Node Bandwidth:
- Commitments & proofs per node:
- 256 row commitments + (256 proofs per element in column * 4 column downloads) = 1280 commitments and proofs
- 1280 * 48 bytes per KZG commitment and proof = 60 KB
- Data per node:
- 256 rows * 16 elements per row in column * 32 bytes per element * 4 column downloads = 512 KB
- (60 + 512) / 12 s block time = 47.7 KB/s
Network Bandwidth:
- 32 MB original data block / 12 s block time = 2.7 MB/s
Celestia
Settings:
- Maximum original block size: about 88 MB (437 rows by 437 columns)
- Block time: 3 s
Node Bandwidth:
- Due to FBSS, node bandwidth is almost identical to the network bandwidth (see below)
Network Bandwidth:
Avail DA
Settings:
- Maximum original block size: 2 MB (256 rows by 256 columns)
- Block time: 20 s
- Columns: 256
- Note: only 50% of each column are downloaded due to local reconstruction
Node Bandwidth:
- Commitments per classical full node:
- 256 commitments * 48 bytes per KZG commitment = 12 KB per block
- Data per classical full node:
- 2 MB = 2048 KB (only downloading original data)
- (12 + 2048) / 20 s block time = 103 KB/s
Network Bandwidth:
- 2 MB original block size / 20 s block time = 0.1 MB/s